Breaking the Chain: Simple Word Swaps Expose LLMs’ Reasoning Limits
Key Findings: Large Language Models (LLMs) exhibit significant limitations in handling sequentially dependent operations. Our simple word-swap experiment reveals that most models struggle to perform correctly beyond two consecutive word swap operations, highlighting a critical weakness in their sequential reasoning.
Read more
Charlie Mnemonic – Update 5: Introducing Chain-of-Thought and Integrated Recall System
We’re excited to announce the fifth major update to Charlie Mnemonic, your open-source AI assistant with Long-Term Memory. This release brings groundbreaking features, including Chain-of-Thought reasoning and an integrated Recall system that allows you to effortlessly search and reference past.
Read more
Discover the LTM Benchmark at NeurIPS 2024
We are glad to announce that our paper “Beyond Prompts: Dynamic Conversational Benchmarking of Large Language Models” has been accepted to NeurIPS 2024, where we will have the opportunity to share our work and knowledge in relation to Long-Term Memory.
Read more
Major Charlie Mnemonic update released!
We are announcing major updates for Charlie Mnemonic, your AI assistant with Long-Term Memory that’s getting smarter and more capable every day. We’ve been working hard to integrate new features and improve existing ones, and we are excited to share.
Read more
Society for Resilient Civilization – a Manifesto
Summary: AI’s Role and Humanity’s Future: AI’s advancement prompts questions about humanity’s role and the need for a resilient society guided by values. Society for Resilient Civilization: The “Society for Resilient Civilization” is proposed, aiming to ensure AI benefits all,.
Read more
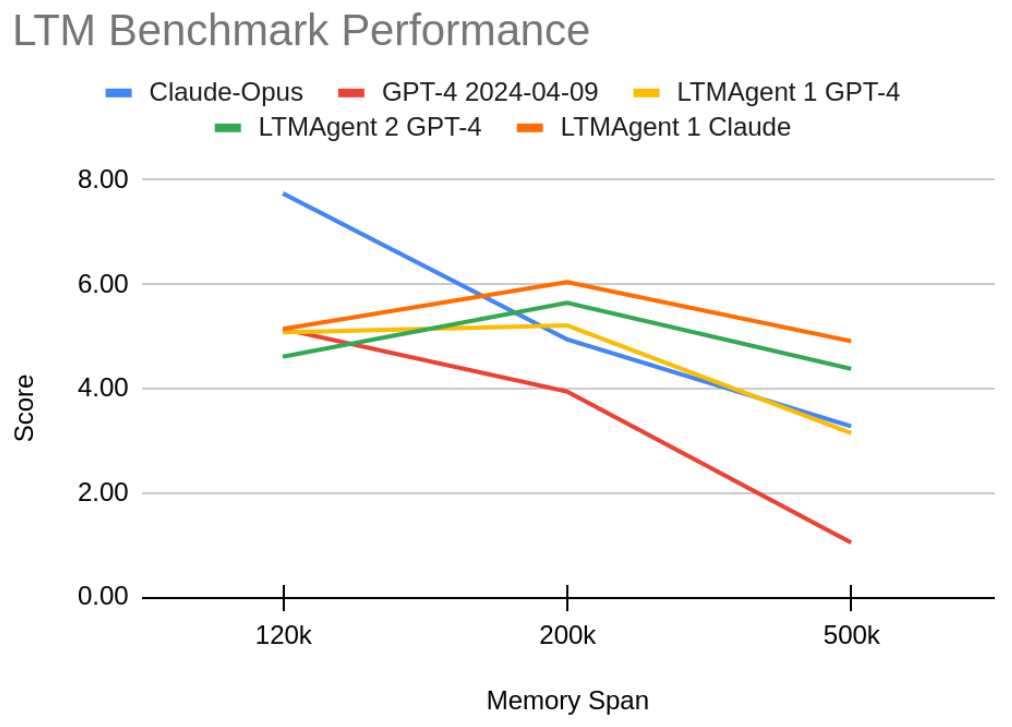
GoodAI LTM Benchmark v3 Released
A Standardization Release: The main purpose of the GoodAI LTM Benchmark has always been to serve as an objective measure for our progress in the development of agents capable of continual and life-long learning.
Read more
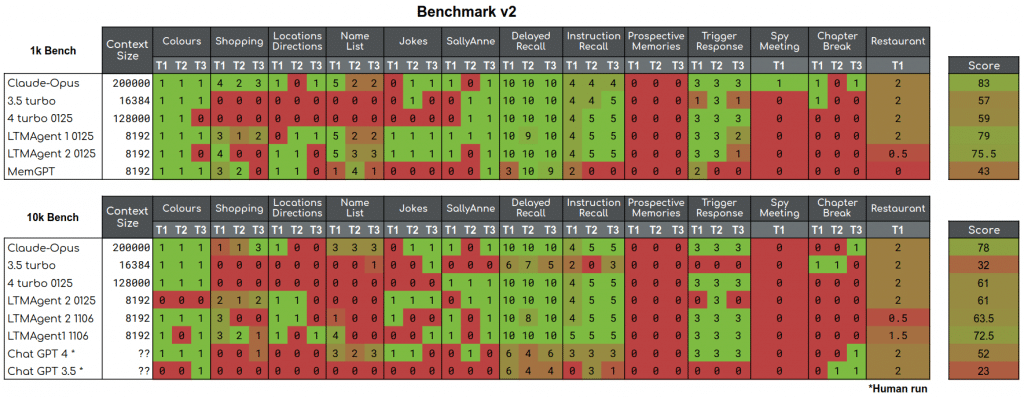
LTM Benchmark: Improvements and new reports
Note: This post is part of a series of blogposts on the LTM benchmark. In the first post we outline our motivation for the benchmark, and in the next post we describe the current results. At GoodAI, we are committed to.
Read more
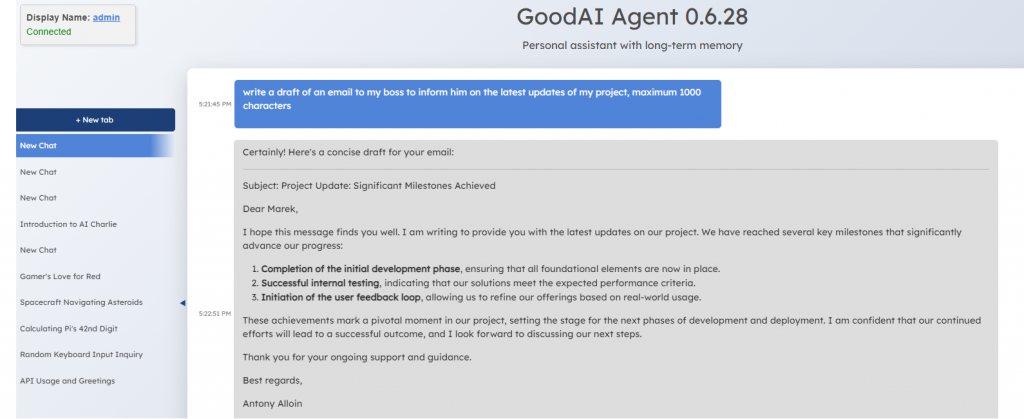
Introducing Charlie Mnemonic: The First Personal Assistant with Long-Term Memory
As part of our research efforts in continual learning, we are open-sourcing Charlie Mnemonic, the first personal assistant (LLM agent) equipped with Long-Term Memory (LTM).
Read more
Introducing GoodAI LTM Benchmark
As part of our research efforts in the area of continual learning, we are open-sourcing a benchmark for testing agents’ ability to perform tasks involving the advanced use of the memory over very long conversations.
Read more
HALLM: An Agent that Observes and Acts through a Python Terminal
At GoodAI, we are deeply committed to the advancement of safe AGI. Large language models (LLMs) undoubtedly offer significant power, but on their own, they have limitations — notably, the inability to learn new skills post-deployment. It's here that our.
Read more