By Simon Andersson
GoodAI
Summary
- AI agents need to use past experience to select the right actions
- Simultaneously learning to remember the past and to use the experience might overwhelm current recurrent neural network (RNN) architectures
- Our distributed Badger architecture, where each agent is composed of interacting experts, faces the additional challenge of learning to communicate internally inside the agent
- Augmenting experts with episodic memory, dedicated to recording observations and internal states, is a possible way to make learning more tractable
- Our experiments suggest that episodic memory can improve accuracy, sample efficiency and learning stability in single- and multi-agent settings
Badger architecture and memory
AI agents often operate in partially observable environments, where only part of the environment state is visible at any given time. An agent in such an environment needs memory to compute effective actions from the history of its actions and observations. The agent, then, is faced with the difficult problem of simultaneously learning to maintain a representation of its history and to compute the right actions from it.
In the Badger architecture, an agent consists of many smaller communicating agents, called experts. This adds an additional component to the learning problem: experts need to learn to communicate while also learning to remember and act.
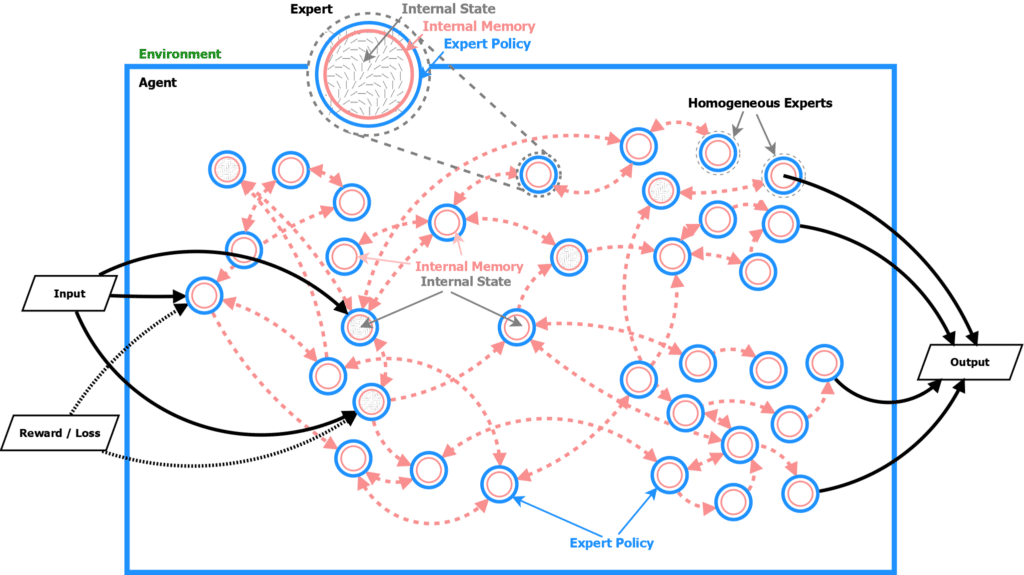
The Badger architecture
In most agent architectures, the memory is maintained in the activations of a recurrent neural network (RNN), the weights of which need to be learned. The training of RNNs presents an additional challenge. The activations of a recurrent network are produced by the repeated multiplication of its weight matrix, and the error signal backpropagated through time can grow or decay exponentially. This is the familiar problem of exploding or vanishing gradients.
It is possible that current RNN architectures, such as long short-term memory (LSTM) and gated recurrent units (GRU), are insufficient for providing the memory for experts. Can we expand the learning capabilities of experts by equipping them with better memory? We are doing some experiments to find out.
A promising idea is to extend experts with episodic memory, allowing them to store and recall past memory states. In meta-learning and similar settings, where an outer loop trains an agent to perform learning or inference over the multiple time steps of an inner loop, the memory may help both to speed up convergence in the inner loop (since observations, once encountered, are retained in memory) and in the outer loop (since the inner loop task is now easier).
We implemented an episodic memory neural network model and found that the memory can improve results on sequential classification (single expert) and a decision task with an agent composed of multiple experts. In the latter experiment, each expert was extended with its own episodic memory.
Episodic memory in humans and machines
In humans, episodic memory is our ability to recall past events, places, and mental states. This is distinct from the more abstract semantic memory and from implicit memory. Our current perceptions and mental state affect what memories we will recall; we attend to memories relevant to the situation at hand.
In recent years, there has been a growing interest in augmenting artificial neural networks with episodic memory. Similar to human episodic memory, the memories are designed to record, at each simulation time step, the model’s perceptions and states and to recall information relevant to the current situation.
Other techniques exist for improving the memory of neural networks. In reinforcement learning, replay buffers are often used to expose models repeatedly to earlier experiences. These experiences are sampled either randomly or using error information known at training time, in order to improve training. In contrast, episodic memory extends the agent’s memory at inference time and relies on its ability to decide the degree to which recorded experiences are similar to what it currently sees.
Neural network model for episodic memory
General idea
Episodic memory can be added to a neural network model by extending an RNN with a larger external memory. This relieves the RNN of the task of maintaining memory over long stretches of time for later recall. Instead, it functions as a memory controller.
A vector output by the RNN (the interface vector) defines what to write to the memory and what to read from it. The data read from the memory (the read vector) is then presented to the RNN as part of its input in the next time step.
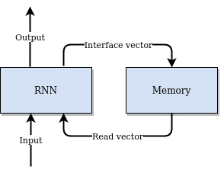
Episodic memory controlled by an RNN
Model
Early work in memory augmentation, starting with the Neural Turing Machine (NMT) of (Graves et al., 2014), sought to construct models that could write to memory with a high degree of flexibility, choosing when and where to write. This turned out to make models very hard to train (Pritzel et al., 2017).
A simpler approach is to write at every time step to a predetermined memory location, appending the new memory to the existing buffer. Following this idea, we implemented an episodic memory similar to the memory recall agent (MRA) of (Fortunato et al., 2019). In this model, the expert’s experiences are stored in a two-dimensional memory matrix, with each row recording the state at a single time step. The memory is treated as a circular buffer, with new memories overwriting old ones once the buffer is filled.
Memory is read by attending over the memory matrix, producing a weighted sum of the memories most similar to the query. The memory resembles an associative array where the values are composed of hidden states and inputs from past time steps. Keys and queries are computed from hidden states and inputs using linear layers.
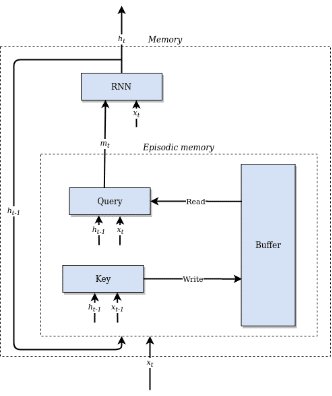
Episodic memory module
Writing
At each time step, the input xt, the hidden state ht (output by the RNN), and a key computed from xt and ht are recorded into a row in the memory matrix. The key is produced by a linear layer. Making the key depend on xt and ht lets the agent associate memories both with what it sees and what it thinks.
Reading
In the read operation, a query is computed by a linear layer from the input xt and the last hidden state ht-1. The K rows with keys most similar to the query are selected from the buffer. A weighted sum is then computed, where each row is multiplied with its similarity (dot product) with the query. This is the memory mt.
Module implementation
Conceptually, operations happen in the order read – RNN step – write. In our implementation, the order is write – read – RNN step, with the write using the input of the preceding time step. The effect is the same, and allows us to put reading and writing together in a single episodic memory module. The module takes the input xt and the last hidden state ht-1 as its inputs and outputs the concatenation of xt and the memory mt.
The complete memory module, encompassing the episodic memory and the RNN controller, has the same interface as an RNN, taking an input xt and outputting a hidden state ht. This means that it can be used as a drop-in replacement for an RNN.
Results
Augmenting RNNs with episodic memory made agents learn more reliably, with less data, and to higher accuracy on two test tasks. We compared an unaugmented LSTM with the combination of LSTM and episodic memory on a sequential version of MNIST digit classification. The agent was fed a sequence of pixels, seven pixels per time step, and asked to classify the digit at the end of sequence. The LSTM achieved an accuracy of 90% after 20 epochs and did not improve with further training. The memory-augmented classifier achieved 94% after 20 epochs and 96% after 50.
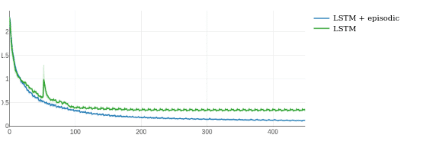
Sequential MNIST classification. Training loss over 50 epochs
Moving on to multi-expert decision problems, we considered a guessing game where the agent has to infer the values of a vector while given as input a scalar error, the difference between the target and its last guess, to improve its decision. The agent consists internally of multiple experts, each containing an RNN, that need to collaborate to produce the output.
In this task, we achieved better results with GRUs than with LSTMs. We compared a GRU without episodic memory with a memory-augmented GRU. We found that when episodic memory was added, the task was learned more reliably and in fewer training episodes.
In the above experiments, we observed improved accuracy and a reduction in the number of outer loop steps required for convergence. For future work, we are interested in learning more about how the memory changes inner loop learning.
Limitations and next steps
While the first results are encouraging, the implemented model still has important limitations.
We have found that multiple slots in the memory often repeat very similar information. Online clustering, i.e., the merging similar of memory entries, could allow more efficient utilization of memory.
A potentially important feature still missing in our implementation are auxiliary losses such as contrastive predictive coding (CPC) and reconstruction loss. Such self-supervised losses can lead to more meaningful representations and have been found crucial for performance on many tasks (Fortunato et al., 2019).
Training the model is computationally demanding and requires large amount of GPU memory. This makes it harder to train large memories.
Many of the model’s limitations are related to how information is represented in memory. Learning representations that are more compressed, more abstract, and more effective in supporting agent action, will be important challenges for future work.
We think episodic memory has considerable potential to improve learning in the multi-expert Badger architecture. The most obvious way to go about this will be to augment each individual expert with its own memory. Another possibility might be to introduce shared memory. This could allow experts exploring different regions in a solution space to share their knowledge.
References
Graves, Alex, Greg Wayne, and Ivo Danihelka. “Neural Turing machines.” arXiv preprint arXiv:1410.5401 (2014).
Fortunato, Meire, Melissa Tan, Ryan Faulkner, Steven Hansen, Adrià Puigdomènech Badia, Gavin Buttimore, Charles Deck, Joel Z. Leibo, and Charles Blundell. “Generalization of Reinforcement Learners with Working and Episodic Memory.” In Advances in Neural Information Processing Systems, pp. 12448-12457. 2019.
Pritzel, Alexander, Benigno Uria, Sriram Srinivasan, Adria Puigdomenech Badia, Oriol Vinyals, Demis Hassabis, Daan Wierstra, and Charles Blundell. “Neural episodic control.” In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 2827-2836. JMLR. org, 2017.
Collaborate with us
If you are interested in Badger Architecture and the work GoodAI does and would like to collaborate, check out our GoodAI Grants opportunities or our Jobs page for open positions!
For the latest from our blog sign up for our newsletter.




